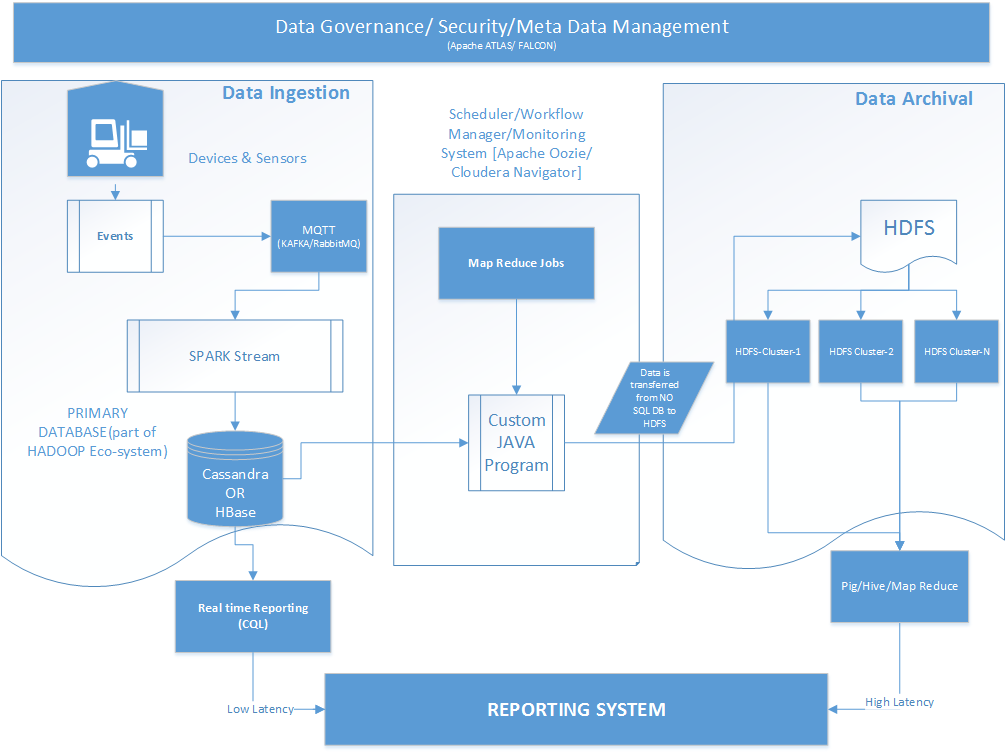
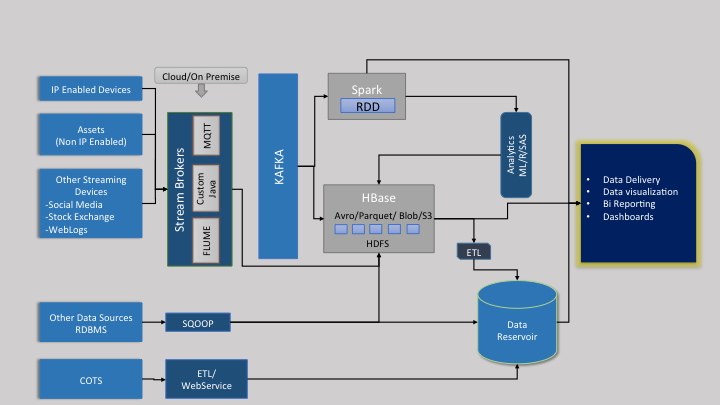
The architecture takes into account a real time IoT scenario.
Events are raised by Industrial Assets/Sensors on a periodic basis. These events will be intercepted using any standard MQTT broker [RabbitMQ, Apache Kafka, etc ] The Message Broker through its subscribing mechanism will ingest the streaming data in a Cassandra Database using Apache SPARK Stream. The Apache SPARK Streaming will ingest the data on a periodic basis the data coming from the assets/sensors. Here as a data store – Hbase can also be utilized instead of Cassandra.
Based on the frequency and the amount of data that these sensors emit, the volume of data ingested can be significantly high. To handle such huge volume of data, an archival system will be developed. Map Reduce Batch Jobs along with custom Java application will push to Hadoop’s File System (HDFS) from the Cassandra. These Map Reduce jobs will be scheduled on a periodic basis and various scheduling tools like Apache Oozie can be utilized. Since we are planning to develop in Cloudera environment, Cloudera Navigator can also be utilized in this regard.
A reporting system will be there to view the health and another Predictive information of the data coming from these industrial assets. The reporting system can query either the Cassandra data store or the HDFS to show the necessary information to the user. The reports queried from the Cassandra system will be of low latency ones while those queried from the HDFS will be of high latency ones. Hive (HQL) / Pig / Map Reduce Jobs will be used to display the reports to the end users. For real time reporting Cassandra Query Language (CQL) can be utilized.
The entire workflow’s Security, Meta-Data Management will be handled by a Data Governance system. Tools like Apache ATLAS/ FALCON will be utilized to create this data governance system.
The cloud environment used here will be AWS.
The architecture diagram below provides more insights of the entire system: