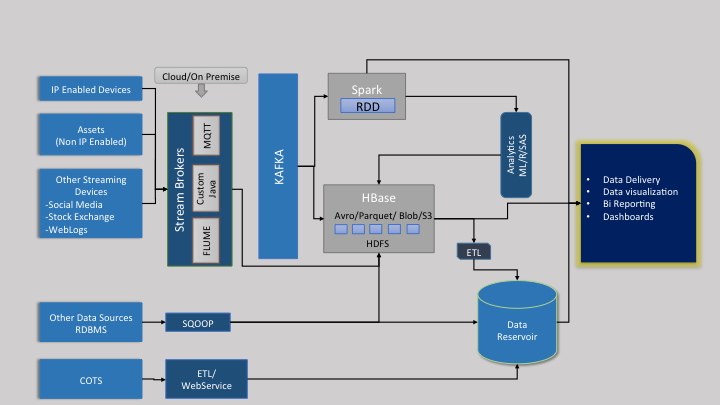
Data can be raised from various sources like an IoT Device, IP/Non IP enabled industrial Asset, Streaming sources (stock exchange/Social Media) or from any COTS [ https://en.wikipedia.org/wiki/Commercial_off-the-shelf ] source. These streaming source of data can be intercepted by standard Stream Brokers like KAFKA, RabbitMQ or by Apache Flume. The Stream Broker systems will pass the control to a SPARK System for realtime data processing. The Stream Broker System at the same time will help to store the structured/unstructured data in a Hadoop system. Different database systems like Apache Parquet, Apache Avro, S3 or a Blob store can be used for different use cases. The SPARK system can be utilized to run any complex analytics and store the rolled up/ aggregated data in the Hadoop system for analytical processing. The processed data can be saved in a data reservoir for faster data access.
***** Apache TEZ can be used instead of the Apache SPARK system
The architecture diagram below provides more insights of the entire system: